Suppose you have run a regression with a large number of observations, say 1,000, or 10,000 or even more. Such a data set with a large or massive sample size is so cheap and widely available in this era of big data. And we all have learned from statistics classes that a larger sample is a better sample: was this a promise of the central limit theorem?
Most likely, your regression results look like this:
1. The t-statistics for many (if not all) regression coefficients are statistically significant at a conventional level;
2. The F-statistic for joint significance of all slope coefficients (H0: R² = 0) are large and its p-value is 0;
3. However, the value of R² is low, sometimes very low; and
4. Many (if not all) model diagnostics or specification tests deliver clear rejection of the null hypotheses, telling you that your model is wrong or incorrectly specified.
The low R² and negative results from model diagnostics do not seem to matter too much, as long as you have highly significant t-statistics and F-statistic?
But you may have wondered why a model with a low value of R² and possibly incorrect specification gives the regression coefficients that are statistically significant. Isn’t this somewhat (if not entirely) conflicting?
In fact, this phenomenon is a sign of big mistake we can make with big data: see this article by Tim Harford.
To get down to the bottom of this, we will need to understand these three points:
1. The modern statistics follows the methods developed in the 1920’s by Student and Fisher, which fundamentally were a small-sample analysis: see this article. The methods were never intended for such a large sample of the big data era, which was simply unthinkable then;
2. A foundation of the modern statistics is random sampling from a single well-defined population. It is unlikely that the found data (the data collected for some other purpose by someone who is willing to make the data available for testing) widely used in big data analysis satisfies this condition. In fact, found data are messy and subject to systematic biases: see again the article by Tim Harford.
3. The central limit theorem is not about getting as large sample as possible. The theorem is about approximating the unknown small-sample distribution, using the large-sample distribution that is known analytically. It does not mean that a large sample is a silver bullet to all statistical problems. Again, the theorem is valid under a range of strict assumptions, which are unlikely to work for found data.
There are two main reasons as to why the modern statistical methods run into serious problems with a large or massive sample. To explore these two reasons, we begin with the quotes by the two authorities of statistical thinking:
1. “Genuinely interesting hypotheses are neighbourhoods, not points. No parameter is exactly equal to zero; many may be so close that we can act as if they were zero”: Leamer (1988);
2. “All models are wrong, but some are useful”: Box (1976)
To explore the first, consider, as an example, a simple linear regression model of the following form:
Y = α + β X + u.
Suppose you want to test for H0: β = 0; H1: β > 0 (without loss of generality). Many modern theoretical theories and methods are built on the condition that the null hypothesis is exactly and literally true so that the value of β = 0 under H0 (what is called a sharp null hypothesis).
However, no parameter can exactly be 0 in practice, as Leamer argues.
Suppose Y is an effect of a treatment X. For example,
Y: Cancer rate among adults; X: Amount of their daily coffee intake
Suppose there is no compelling medical reason to believe that there is an effect. However, can the effect be 0 exactly and literally so that β = 0? In an observational study, it is most likely that the true value of β is non-zero, but clinically negligible. That is, there is an effect, but it is not large enough to matter clinically and can be ignored practically. Let us assume that such a value of β is 0.01.
Consider a simple case where the error term u is generated from a normal distribution with zero mean and known variance. Then, the sampling distribution of the least-squares estimator b for β can be written in two equivalent forms as below, given the sample size n and a variability measure σ:


These normal distributions are plotted below for different values of sample size n and β, given an appropriate value of σ, as below:

The distribution of the least squares estimator b for β: Image provided by the author
Under H0: β = 0, the distribution of the least-squares estimator b for β is the black curve, whatever the value of n is. The critical value to reject or not to reject H0 is obtained from this distribution. That is, reject H0 at the 5% level of significance if Z > 1.645.
Now, as we assumed, β = 0.01 in population. When n = 10, the distribution of the Z statistic is the red curve; while, when n = 10000, the distribution of b is the blue curve. These are the distributions from which the test statistic Z is actually generated if β = 0.01.
This means that, while the null hypothesis is violated by a negligible margin (β = 0.01), the test statistics (Z) are generated from the blue curve when n = 10000, not the black curve. Hence, with the 5% critical value of 1.64 (obtained from the black curve), the test statistics are always greater than 1.64 and the probability of rejecting H0 is 1. That is, when the sample size is massive, you will always reject H0, even if the null hypothesis is practically true. If you do reject H0 in this case, you are practically committing a Type I error.'
This was not a problem in the era where Student and Fisher lived. Because, when n is as small as 10, the test statistics are generated from the red curve, which is nearly identical to the black one.
This example demonstrates that the statistical method we employ may work with a small data set, but it will be problematic with a big one. And this problem is applicable to almost all statistical tests in use in modern days: see the case of the F-test in this post.
Now we explore the second point above. All models are wrong, but can they be useful when the sample size is massive? Suppose the true model is
Y = α + β X + γ W + u,
and you are fitting a wrong model
Y = α + β X + u.
This is a well-known case of omitted-variable bias. Here, the bias of the least-squares estimator b for β is given by
Bias(b) ≡ E(b) — β = γδ,
where δ is the slope of the regression of W on X. In the distributional form, it can (loosely) be written as
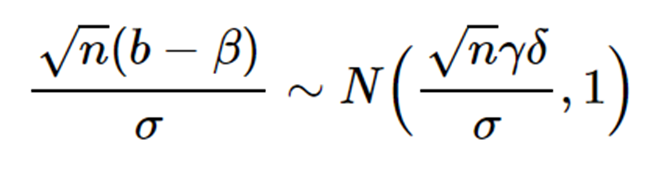
As indicated above, the omitted model bias grows sharply with the sample size. A wrong model can still be useful when the sample size is small where the bias may be tolerable. However, the model will not be useful at all, when the bias is inflated by a massive sample size. That is, a model with a massive sample size may return the parameter estimates which are massively biased.
Modern statistical methods are built on the two assumptions that we discussed above:
1. The null hypothesis holds exactly and literally;
2. The model is correct (again exactly and literally).
In this article, I argue that these two assumptions are often practically violated and demonstrate that the associated problems get worse with increasing sample size. The central limit theorem is often misinterpreted with a wrong belief that a large or massive sample is a silver bullet to all the problems of data science. It may be so in an ideal world where all the critical assumptions are satisfied, but the reality of course is far from it.
Researchers should be reminded and cautioned that too much trust on big data can be dangerous, as we have seen in the case of Google Flu Trends: see again Harford.
As instructed from the two recent statements from the American Statistical Association (Statement 1, Statement 2), we need to be “thoughtful, open, and modest” about the way we interpret the statistical results from big data and the dangers that come with them. In the big data era, we should embrace the statistical methods with a new direction, new approaches, and new ways of statistical thinking.

Comments